테이블이란 ? 데이터를 관리 및 저장하는 장소, 효율적인 관리 및 적절한 조작이 매우 종요하고 실생활에서 광범위학게 사용되는 2차원 표와 유사하다.
테이블 설계 규칙
집합을 나누는 방법
집합을 나누는 방법에 따라 한개 혹은 여러개의 테이블이 될 수 있다.
예를 들어서 회원 테이블을 관리하고 있었는데, 새로운 기준이 적용 되어서 회원을 일반 회원과 프리미엄 회원 테이블로 나누는 경우가 이에 해당한다.
데이터 베이스 vs 자바
데이터 베이스는 자바와 비교 될때가 많다.
데이터베이스에서 테이블은 자바에 클래스와 비교되고, 열은 클래스의 속성과 비교된다. 또한, 행은 자바에서 인스턴스와 비교되기도 한다.
기본키
기본키는 특정 집합에서 특정 행을 유일하게 식별할 수 있는 속성의 집합이다. 예를 들면, 학번, 카드발급번호, 주민등록번호 등이 있다.
따라서 중복된 식별을 없에기 위해서 기본키는 중복 되면 안된다. 또한, 한번 정해지면 가급적 변경하지 않도록 한다.
기본키는 Null 값이 허용 되지 않는데, 업무 상의 이유로 기본키가 없는 테이블이 운영되는 곳이 간혹 있다.
정규형
테이블을 제대로 된 형태로 만들자고 하는 것인데, 테이블을 쪼갤 수 있는 부분까지 쪼개는 것을 의미한다.
제 1 정규형(1NF) 위반
테이블의 셀에 여러 개의 값을 포함하지 않는다.
예를 들어 회원 테이블에서 연락처를 컬럼을 전화번호, 이메일로 같이 관리하는 경우가 1 정규형 위반에 해당한다.
1 정규형 해소를 위해서는 기존에 회원 테이블에서 연락처를 분리해서 회원 연락처 테이블을 만들고 연락처 구분 컬럼을 만들어 핸드폰인지 이메일인지 구분해서 저장해야 한다.
함수 종속성 ?
테이블은 함수오 같다. -> 기본키의 값을 입력하면 특정 출력 값이 나오는 구조이기 때문이다.
예를 들어 환율 테이블에 경우 어떤 통화인지 기본키를 입력하면 환율이 나오는 방식으로 생각할 수 있는다. 어떤 값에 의해 값이 리턴되는 형식에 함수와 같다고 할 수 있다.
제 2 정규형(2NF) 위반
부분 함수 종속성을 허용하지 않음..
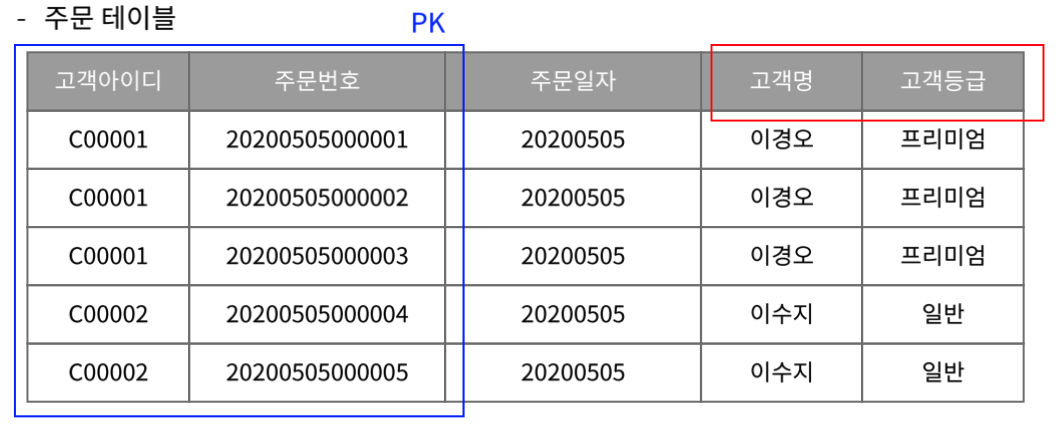
부분 함수 종속이란 기본키를 구성하는 열의 일부에만 함수 종속이 존재 하는 것을 의미하는데, 예를들어서 주문 테이블은 고객 아이디와 주문번호를 복합키로 사용해서 주문을 구별한다. 주문 일자에 경우 고객 아이디와 주문번호를 통해서 주문 일자가 나오는게 맞는데 고객명과 고객등급은 복합키가 아닌 고객 아이디만 사용해도 알 수 있다. 이 경우 제 2 정규형 위반이라고 한다.
해소 하기 위해서는 고객 주문 테이블에서 고객명과 고객등급 컬럼을 삭제하고 고객 테이블을 따로 만들어서 부분 함수 종속을 제거해야 한다.
제 3 정규형(3NF) 위반
기본 키를 제외한 일반 컬럼끼리 함수 종속이 발생한 경우에 위반했다고 한다.
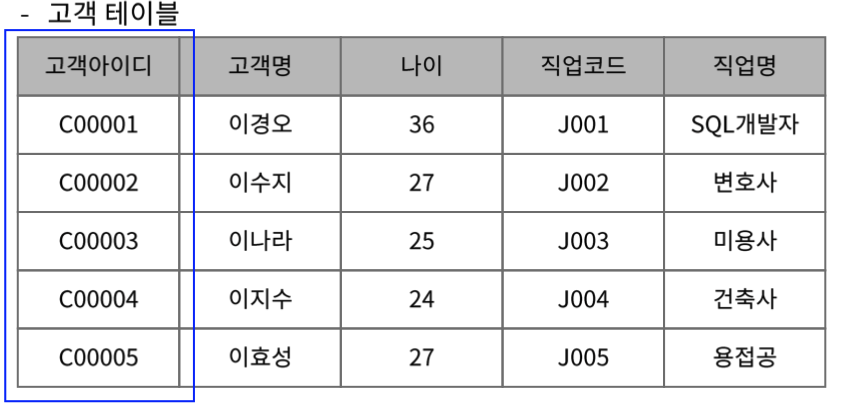
예를 들어서 고객 테이블에 경우 고객 아이디를 통해서 고객 명과 나이가 판단되는 것은 맞지만 일반 컬럼인 직업코드와 직업명은 서로간에 함수 종속이 발생했다. 이경우 제 3 정규형 위반이라고 하고 해소 하기 위해서 고객 테이블에서 직업 명 컬럼을 삭제하고 직업테이블을 새로 만들어서 직업 코드 별 직업명을 확인하도록 한다.
4, 5 정규형
일반적으로 거의 쓰이지 않아서 따로 찾아볼것.. 3 정규형 까지는 확실히 알도록 하자.
ER 다이어 그램
데이터 모델링 문야에서 개체-관계 모델이란 구조화된 데이터에 대한 일련이ㅡ 표현이다. 개체-관계 모델리을 하는 것을 ERM(Entity-Relationship Modelling)이라 하고 이에 대한 산출 물을 ERD(Entity-Relationship Diagram) 이라고 한다.
클라이언트 요청에 대한 응답시간(Response Time) 과 시간당 처리할 수 있는 처리량(Throughtput) 이다.
용어 알아보기
Corrent User = Active User + Inactive User : 현제 사용자를 의미하는데 서버에 부하를 일으키는 Active User와 서버에 부하를 일으키지 않는 Inactive User로 나뉜다.
TPS : 서버가 일정 시간 내의 처리한 트랜잭션의 양
Response Time : 요청 후 응답을 받을 때 까지 소요된 시간
Resource : 한정된 값을 가진 시스템의 구성요소
성능의 특성
경합 부하 구간에서 Response Time이 급격하게 늘어나게 된다.
데이터베이스 병목의 원인
여러 요인이 있지만 DBMS 내부 I/O 병목으로 인한 대기시간 증가가 가장 큰 이유이다. 대부분은 I/O(Sleep) 에서 발생힌다.
병목현상을 해결하기 위해서는
절대적인 블록 I/O 를 줄여야 함.
블록 I/O를 줄이기 위한 모델 설계, DBMS 환경 구축, SQL 튜닝등의 기술이 필요함.
포로세스 생성 주기에 영향을 받는다.
여러 프로세스가 하나의 CPU를 공유 할 수 있지만, 특정 순간에는 하나의 프로세스만 CPU를 사용한다. 디스크에서 데이터를 읽어야할 땐 CPU를 OS에 반환하고 잠시 수면 상태에서 I/O 가 완료되기를 기다린다. 즉, SQL 문에서 발생하는 절대적인 I/O 횟루를 줄이는 것이 성냉 개선의 핵심이다.
성능을 결정하는 요인
성능을 결정하는 가장 큰 요인에는 옵티마이저의 성능이 있다. 사용자가 SQL 문을 입력하면 옵티마이저는 파싱한 SQL를 최적화하여 프로시저로 변환시키는 작업을 한다.
옵티마이저는 통계정보를 이용해 각 실행 계획의 예상 비용을 산정한 후 최저 비용을 나나태는 실행 계획을 선택한다.
옵티마이저가 참조하는 통계정보
SQL 파식 -> 실행계획 작성 ( 통계 정보 활용) -> 실행계획 선택 ( 옵티마이저의 역활) -> SQL 실행
통계정보 :
테이블의 행수
데이터형
크기
제약정보
인덱스에 대한 통계
열 값에 대한 통계 등등..
실행 계획은 어떻게 세워지는
인덱스
지정한 컬럼을 기준으로 메모리 영역에 일종의 목차를 생성하는것, 조회 할때는 좋은 성능을 보이만, insert, update, delete 등의 작업을 해야 할때에는 인덱스 테이블까지 변경해하는 상황이 발생하면서 오히려 성능이 안좋을 수 있다.
``SQL CREATE INDEX IDX_TB_EXECUTION_TEST_01 ON TB_EXECUTION_TEST(CUSTOMER_ID);
1 2 3 4 5 6 7 8 9
인덱스는 B-Tree를 사용하여 테이블을 조회한다. 반면에, 인데스가 없는 조회 조건은 모든 요소를 비교하면서 조회하게 된다. 이를 Table Full Scan 이라고 한다.
반면에 인덱스를 사용하면 B-Tree를 이용하여 Range Scan 을 하게 된다.
먼저 branch 노드에서 커르고 리픝 노드에서 수평적으로 검사하여 디스크에 접근 하는 것이다.
인덱스를 사용할 컬럼은 카디너리티가 높은 컬럼을 사용해야 한다. 카디널리티는 Distint 명령을 수행했을때 숫자 라고 생각하면 쉽게 생각 할 수 있는데, 성별보다 주민등록 번호가 카디너리티가 높다는 것은 여기에 기인하여 생각할 수 있다. 여러 컬럼으로 인덱스를 사용할때에는 카디너리티가 높은 순에서 낮은 순서로 사용해야 한다.
WAL(Write-ahead logging)이라고 부르면, 시스템에서 모든 수정은 적용 이전에 로그에 기록된다. 예를 들어서 특정 프고그램이 진행되는 동안 정전이 일어났다고 가정해보자. 다시 시작할 때 프로그램은 어느 작업이 수행을 성공적으로 마쳤는지, 실패했는지 등의 정보를 알고 있어야 한다. 로그 선행 기법을 사용한다면 프로그램은 이러한 로그를 검사하여 예기치 않은 정전 시 해야 할 일과 실제 했던 일을 비교하게 된다.
데이터베이스 버퍼
데이터 파일로의 입력을 데이터 베이스 버퍼를 경유해서 하도록 한다. (성능 양립을 위해서 )
순서 :
갱신 대상의 데이터 포함한 블록이 버퍼풀에 있는지 확인
없을 경우 데이터 파일로부터 해당 블록을 읽어 들임.
버퍼 풀 내의 해당 블록을 갱신 수행
갱신 내용이 Commit 과 함께 로그에 기록
갱신 되었지만 데이터 파일에 쓰이지 않은 블록은 Dirty 블록이 됨.
갱신된 데이터 블록은 나중에 정리되어 데이터 파일에 적용됨(체크 포인트)
체크포인트 이전 로그 파일은 불필요 하게 됨
갱신과 더불어 위 순서 반복
Crash 복구 흐름
Crash 가 발생하면
WAL : 마지막으로 Commit 된 트랜잭션의 갱신 정보 가짐
데이터베이스 버퍼 : Crash 로 내용이 전부 소실
데이터베이스 파일 : 최후 체크포인트까지의 갱신 정보 가짐.
-> 데이터 베이스 파일을 Crash 전 최신 Commit 상태로 수정함.
백업 및 복구
백업의 3가지 관점
핫 백업과 콜드 백업
논리 백업과 물리 백업
풀 백업과 부분(증분/차등) 백업
핫백업과 콜드 백업
핫 백엄 : 온라인 백엄/ 데이터 베이스 기능 이용, 데이터 베이스를 정지 하지 않고 백업 데이터를 얻음
콜드 백업 : 오프라인 백업 / OS 기능 이용, 서버를 내림고 데이터 베이스도 종료 시키고 OS 명령으로 복사
다시 작업하던 brnahc로 이동하고 마찬가지로 작업 완료, 테스트 진행 후 운영 브랜치로 머지한다.
브랜치의 기초
회사 내의 새로운 53번 이슈를 해결해야 한다면 다음과 같이 브랜치를 만들고 동시에 switch 할 수 도 있다. 옵션 플래그는 -b 이다.
1 2
$ git checkout -b iss53 Switched to a new branch "iss53"
이제 iss53 브렌치에서 작업을 진행하고 커밋한다.
1 2
$ vim index.html $ git commit -a -m 'added a new footer [issue 53]'
그러면 main 브렌치보다 커밋을 하나 더한 상태가 된다. 이때 어떤 문제가 생겨서 빨리 해결해야 한다고 가정하자. 이를 해결 하기 위해서 우선은 main 브랜치로 이동하고 HotFix 브랜치를 만들어서 기존에 작업하던 iss53에 영향을 안주고 고칠 수 있다. 먼저 main 브렌치로 옮긴다. 아직 커밋하지 않은 checkout 브랜치와 충돌을 발생시킬수도 있는데 우선은 모두 커밋한 후에 main 브랜치로 이동하도록 한다.
1 2
$ git checkout master Switched to branch 'master'
(main 브랜치는 기본 브랜치라는 의미여서 이름은 master 여도 상관 없다. )
이제 hotfix 브랜치를 생성, 전환하고 작업한후 결과를 커밋한다.
1 2 3 4 5 6
$ git checkout -b hotfix Switched to a new branch 'hotfix' $ vim index.html $ git commit -a -m 'fixed the broken email address' [hotfix 1fb7853] fixed the broken email address 1 file changed, 2 insertions(+)
$ git checkout iss53 Switched to branch "iss53" $ vim index.html $ git commit -a -m 'finished the new footer [issue 53]' [iss53 ad82d7a] finished the new footer [issue 53] 1 file changed, 1 insertion(+)
작업을 완료하면 main 브랜치로 전환 한 후에 iss53번 브랜치와 병합한다. 그럼 hotfix 내용이 포함된 main 브랜치에 새로운 iss도 처리한 브랜치로 병합할 수 있다.
Merge 의 기초
1 2 3 4 5 6
$ git checkout master Switched to branch 'master' $ git merge iss53 Merge made by the 'recursive' strategy. index.html | 1 + 1 file changed, 1 insertion(+)
이번에 머지를 진행하면 hotfix 머지했때랑 다른 메세지를 보여준다. 이는 현제 브랜치가 가리키는 커밋이 머지할 브랜치의 조상이 아니므로 fast-foward로 병합하지 못하기 때문이다. 이 경우에 git은 이 둘의 공통 조상이 가리키는 스냅샷과 각각의 스냅샨을 사용한 3-way Merge 실행한다. 각각의 스냅샷을 비교한 후 새로운 커밋을 만들고 그 커밋의 조상이 각각의 브랜치를 바라보게 하는 것이다.
충돌의 기초
3-way Merge를 진행할때 충돌이 발생하기도 한다. 충돌은 merge 하려는 브랜치에서 동일한 작업한 브랜치와 동일한 파일에 내용이 달라서 발생한다. 예를 들어 앞서서 hotfix에서 index.html에 대한 작업을 진행했고, iss53에서도 마찬가지로 index.html에 대한 작업을 진행했으면 아래와 같이 충돌이 발생한다.
1 2 3 4
$ git merge iss53 Auto-merging index.html CONFLICT (content): Merge conflict in index.html Automatic merge failed; fix conflicts and then commit the result.
git status 명령을 입력하여 어디가 충돌이 발생했는지 알 수 있다.
1 2 3 4 5 6 7 8 9 10 11
$ git status On branch master You have unmerged paths. (fix conflicts and run "git commit")
Unmerged paths: (use "git add <file>..." to mark resolution)
both modified: index.html
no changes added to commit (use "git add" and/or "git commit -a")
Unmerged path: 에 있는 파일을 확인하면 된다.
1 2 3 4 5 6 7
<<<<<<< HEAD:index.html <div id="footer">contact : email.support@github.com</div> ======= <div id="footer"> please contact us at support@github.com </div> >>>>>>> iss53:index.html
해당 파일을 열어보면 다음과 같은 표시를 해준다. HEAD 브랜치는 main 브랜치이고 ===== 다음에 내용은 iss53에 내요이다. 이럴때는 HEAD에 내용을 선택할지 iss53에 내용을 선택할지, 아니면 다 섞을지, 내용을 삭제할지 , 새로운 내용을 만들지 정한후 수정하면 된다.
밑에는 새로운 다 지우고 새로운 내용을 추가한 예제이다.
1 2 3
<div id="footer"> please contact us at email.support@github.com </div>
충돌을 해결하고 나서 해당 파일을 커밋하면 merge 에 대한 내용을 보여주고 merge된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Merge branch 'iss53'
Conflicts: index.html # # It looks like you may be committing a merge. # If this is not correct, please remove the file # .git/MERGE_HEAD # and try again.
# Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # On branch master # All conflicts fixed but you are still merging. # # Changes to be committed: # modified: index.html #
깃은 장기적으로 브랜치를 열어두고 새로운 브랜치에서 병합하는것이 굉장히 쉬운 편이다. 이를 활용해서 git에서 많이 사용하는 개발 플로우가 있다.
master 브랜치는 배포했거나 배포할 코드로서 안정적인 버전을 유지한다.
develop 브랜치는 개발을 진행하고 있는 브랜치로 안정화가 진행되면 master 브랜치로 병합된다. 또한 기능 개발시 topic 브랜치를 만들어서 개발, 테스트 후 devlop 브랜치로 머지하고 devlop 브랜치에서 안정화 작업을 거친 후 master 브랜치로 머지하는 방법을 사용한다.
각 브랜치를 하나의 실험실로 생각한다.
Topic Branches
토픽 브랜치는 어떤 한 가지 주제나 작업을 위해 만든 짧은 호흡에 브랜치이다. git 에서는 브랜치를 만드는 것이 매우 쉬우므로 이렇게 브랜치를 생성 하고 개발하고 머지한다음 삭제한다.
보통 주제별로 브랜치를 만들고 각각은 독립돼 있기 때문에 매우 쉽게 컨텍스트 사이를 옮겨 다닐 수 있다. 묶음별로 나눠서 일하면 내용별로 검토하기에도, 테스트하기에도 더 편하다. 각 작업을 하루든 한 달이든 유지하다가 master 브랜치에 Merge 할 시점이 되면 순서에 관계없이 그때 Merge 하면 된다.