render() { const temperature = this.state.temperature; // ...
리엑트는 공유 되는 State를 만들기 위해서 가장 가까운 조상 요소로 state를 옮기는 방법을 사용하는데 이를 Lifting State Up 이라고 한다.
예제에서는 인풋에 조상 요소인 Calculator 가 state를 관리할 수 있도록 하고 props 로 인풋에 온도를 전달해주면 동기화 기능을 구현할 수 있다.
인풋에서 state로 사용하던 temperature 를 props에 temperature 로 변경한다.
1 2 3 4
render() { // Before: const temperature = this.state.temperature; const temperature = this.props.temperature; // ...
props는 읽기 전용이다. 그전에 TemperatureInput에서 변경 됬을때 다시 렌더링 하기 위해서 this.setState()를 호출했던것은 이제 할 수 없다. 대신에 온도 변화에 해당하는 함수인 onTemperatureChange와 같은 함수를 조상 요소인 Calculator에서 만들어서 props로 전달해 주면 똑같은 기능을 할 수 있게 만들 수 있다.
onTemperatureChnage 와 같은 함수 이름은 임의로 정한 것이다 onValueChange 와 같은 이름도 가능하고 마음대로 설정 가능하다.
디자이너가 디자인한 화면을 보고 박스를 그리며 일므을 붙여본다. 이미 그려져 있다면 디자이너와 상의 해보면서 수정하거나 의미를 확실히 파악하도록 해본다.
하지만 어떤것이 컴포넌트가 될지 알수 있을까? 이것은 우리가 함수나 객체를 만들때처럼 생각하면 된다. 한가지 컴포넌트는 한가지 일만 하도록 작게 나누면서 단일 책임 원칙을 지키는 것이다.
JSON 데이터 모델이 적절히 만들어 졌다면 UI와 잘 연결 될 것이다. 이것은 ui와 데이터 모델이 information architecture 을 가지는 경향이 있기 때문이다.
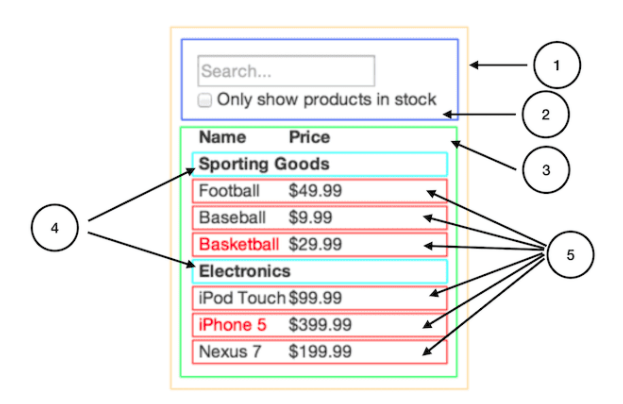
FilterableProductTable(노란색): 예시 전체를 포괄합니다.
SearchBar(파란색): 모든 유저의 입력(user input) 을 받습니다.
ProductTable(연두색): 유저의 입력(user input)을 기반으로 데이터 콜렉션(data collection)을 필터링 해서 보여줍니다.
ProductCategoryRow(하늘색): 각 카테고리(category)의 헤더를 보여줍니다.
ProductRow(빨강색): 각각의 제품(product)에 해당하는 행을 보여줍니다.
3번은 ProductTableHeader로 바꾸어 Name Price만 따로 표현하는게 더 합리적일 수 있다. 그러나 여기선 데이터 콜렉션이라는 역활 책임을 생각해서 남두었다. 뭐가 좋을지는 선택하면 된다.
이제 계층적으로 나타내면 다음과 같다.
FilterableProductTable
SearchBar
ProductTable
ProductCategoryRow
ProductRow
2단계 : React로 정적인 버전 만들기
데이터 모델을 가지고 UI 렌더링은 되지만 상호 작용은 안되는 정적인 버전을 만들어 본다. 정적은 버전은 생각을 적게하고 타이핑을 많이 하고, 상호작용을 위해서는 생각을 많이 하고 타이핑을 적게 하는데, 나중에 살펴 보기로 하고 정적인 버전을 만들어 본다.
정적 버전을 위해서 우선은 state를 사용하지 말아라. 우선은 props로 데이터를 부모에서 자식으로 전달하면서 만들어 보아라.
컴포넌트는 top-down(하양식) 이나 bottom-top(상향식) 으로 만들 수 있다. 간단한 예시에서는 보통 하향식으로 만드는게 쉽지만 프로젝트가 커지면 상향식으로 만드록 테스트를 작성하면서 개발하기가 더 쉽다.
이 단계가 끝나면 데이터 렌더링을 위해 만들어진 재사용 가능한 컴포넌트들의 라이브러리르 가지게 된다. 지금은 render() 메서드만 가지고 있다. 최상위 컴포넌트는 props를 통해 데이터 모델을 받고 자식 컴포넌트에 전달하는데 한번 만들어 봄으로서 이런 흐름을 파악하기 쉽다.
3 단계: UI state 에 대한 최소한의 (하지만 완전한) 표현 찾아 내기
이제 변경해야할 최소한의 state는 무엇일지 생각해본다. TODO 리스트에서 예를 들면 해야할 일 목록을 state를 관리하고, 할일 목록 갯수를 state를 관리하지 않는것을 의미한다. 이것은 중복 배제 원칙이라고 하는데 만약 할일 목록 갯수를 state로 관리하고 싶다면 할일 목록 배열의 갯수를 세는 방법을 사용한다.
다음 목록에서 state가 될만한 것이 무엇이 있을지 생각해 보자.
제품의 원본 목록
유저가 입력한 검색어
체크박스의 값
필터링 된 제품들의 목록
다음 3가지 질문을 통해서 확인할 수 있다.
부모로부터 props를 통해 전달 됩니까? -> state가 아니다.
시간이 지나도 변하지 않나요? -> state가 아니다.
컴포넌트 안의 다른 state나 props를 가지고 계산 가능한가요? -> 그렇다면 state 가 아니다.
결과적으로 state는 다음 목록이 된다.
유저가 입력한 검색어
체크박스의 값
4단계 : state가 어디 있어야 할지 찾기
리엑트는 단방향 데이터 흐름을 갔기 때문에 어떤 컴포넌트에 state를 가지게 할지가 중요하다. 다음과 같은 기준을 생각해서 정해보자.
state를 기반으로 렌더링하는 모든 컴포넌트를 찾으세요.
공통 소유 컴포넌트 (common owner component)를 찾으세요. (계층 구조 내에서 특정 state가 있어야 하는 모든 컴포넌트들의 상위에 있는 하나의 컴포넌트).
공통 혹은 더 상위에 있는 컴포넌트가 state를 가져야 합니다.
state를 소유할 적절한 컴포넌트를 찾지 못하였다면, state를 소유하는 컴포넌트를 하나 만들어서 공통 오너 컴포넌트의 상위 계층에 추가하세요.
결정하는 과정으 다음과 같다.
ProductTable은 state에 의존한 상품 리스트의 필터링해야 하고 SearchBar는 검색어와 체크박스의 상태를 표시해주어야 합니다.
공통 소유 컴포넌트는 FilterableProductTable입니다.
의미상으로도 FilterableProductTable이 검색어와 체크박스의 체크 여부를 가지는 것이 타당합니다.
5단계: 역방향 데이터 흐름 추가하기
우리가 만든 FilterableProductTable 에서 아직 SeacrBar에 setState를 콜백으로 주지 않았기 때문에 폼을 입력해도 데이터가 변하지 않게 된다. 하위 컴포넌트인 SearchBar에서 상위 컴포넌트인 FilterableProductTable에 state를 변경하기 위해서는 콜백으로 setState를 주고 하위 컴포넌트에서 호출하면된다.
Hook은 함수 컴포넌트에서 React state와 생명주기 기능을 연동(Hook Into) 할 수 있게 해주는 함수이다.
hooks 를 사용하면 class 컴포넌트가 아닌 함수형 컴포넌트로 생명주기 메서드와 동일한 기능을 사용할 수 있다.
버튼을 클릭하면 count가 1씩 증가형 rendering 하는 컴포넌트이다. 여기서 useState를 hooks 라고 하고 초기값을 입력하여 호출하면 값과 설정해주는 함수가 나온다. setCount와 같은 메서드는 클래스 컴포넌트에 this.setState와 같다고 할 수 있는데 setState 처럼 꼭 객체를 넣을 필요가 없고, 이전 state와 새로운 state를 합치지 않는다는 차이점이 있다.
jest 는 자바스크립트 코드를 테스트 할수 있게 해주는 도구이다. 패키지만 다운받으면 별도의 설정없이 바로 사용할 수 있는것이 특징이다.
최소한의 설정?
패키지 설정 및 스크립트 설정에 관한 부분으로 거의 할게 없다.
npm init -y : npm 초기화
npm i jest -D : 개발 과정에서만 사용할 것이므로 jest를 -D 옵션을 붙여서 설치한다. –save-dev 와 똑같다.
package.json으로 이동하여 script를 수정한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
{ "name": "jest-tutorial", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "jest"// test 부분에 jest 추가 }, "keywords": [], "author": "", "license": "ISC", "devDependencies": { "jest": "^27.3.0" } }
npm test : 테스트 코드 실행 가능
test 코드는 test.js 등의 이름이나. __tests__ 폴더 아래 있는 모든 파일을 찾아서 실행한다.
matcher
matcher는 테스트에서 예상한 부분과 실제 결과가 맞는지 매칭시키는 함수를 의미한다. jest 다양한 matcher 가 존재하는데 모두다 외울 필요는 없고 필요할때 확인하면 된다. 보통 expect().matcher()를 사용하여 검사하는데 맞지 않는경우를 조사하려면 not을 붙혀서 expect().not.matcher()를 사용하면 된다.
toBe() : 결과가 같은지 확인, 아닌 경우를 판단하려면 expect().not.matcher()를 사용하면 된다.
1 2 3
test("1은 1이야.", () => { expect(1).toBe(1); });
toEqaul() : 결과가 같은지 확인, 배열 객체 등의 요소는 재귀적으로 판단해야 하기 때문에 이것을 사용해야 한다.
jest 는 테스트가 끝나면 바로 끝나버림. 콜백 함수를 넘겨주어도 기다리지 않고 끝나기 때문에 제대로 된 테스트를 진행할 수 없다. 이때는 test네 콜백에 인자로 done을 넘겨주면 된다. 이 done이 호출되면 테스트가 끝났다고 명시할 수 있어서 콜백이 끝나는 부분에서 done을 호출하면 제대로된 테스트를 할 수 있다.
UPDATE PARTS SET COST =130 WHERE PART_ID =1 ; COMMIT;
조건을 입력하지 않으면 테이블에 모든 행을 업데이트 한다. 조건문이 없는 UPDATE, DELETE 문은 DB tools 에서 경고문을 던진다.
1 2 3 4
UPDATE PARTS SET COST = COST *1.05 ; COMMIT;
DELETE
데이터를 삭제한다.
1 2 3 4 5 6
DELETE FROM SALES WHERE ORDER_ID =1 AND ITEM_ID =1 ; COMMIT;
VIEW
VIEW 는 물리적으로 데이터를 저장하지 않는 테이블이라고 생각할 수 있는데 쉽게 생각하면 어떤 SQL에 결과값을 저장해 둔 것이라고 생각하면 된다.
INLINE VIEW
SQL 문 안에서 INLINE VIEW 를 사용할 수 있다.
1 2 3 4 5 6 7 8
SELECT A.*FROM ( SELECT NAME , CREDIT_LIMIT FROM CUSTOMERS )A ;
VIEW
복잡한 쿼리에 대한 결과를 VIEW로 저장해두고 사용할 수 있다. 다음 쿼리는 발송된 주문에 대한 연도별 각 고객의 매출 총 금액을 구하는 SQL 문이다.
1 2 3 4 5 6 7 8 9 10 11 12
SELECT C.NAME AS CUSTOMER , TO_CHAR(A.ORDER_DATE, 'YYYY') ASYEAR , SUM( B.QUANTITY * B.UNIT_PRICE ) SALES_AMOUNT FROM ORDERS A , ORDER_ITEMS B , CUSTOMERS C WHERE1=1 AND A.STATUS ='Shipped' AND A.ORDER_ID = B.ORDER_ID AND A.CUSTOMER_ID = C.CUSTOMER_ID GROUPBY C.NAME, TO_CHAR(A.ORDER_DATE, 'YYYY') ORDERBY C.NAME ;
CREATE OR REPLACE VIEW 로 VIEW를 생성할 수있다.
1 2 3 4 5 6 7 8 9 10 11
CREATEOR REPLACE VIEW CUSTOMER_SALES ASSELECT C.NAME AS CUSTOMER , TO_CHAR(A.ORDER_DATE, 'YYYY') ASYEAR , SUM( B.QUANTITY * B.UNIT_PRICE ) SALES_AMOUNT FROM ORDERS A , ORDER_ITEMS B , CUSTOMERS C WHERE1=1 AND A.STATUS ='Shipped' AND A.ORDER_ID = B.ORDER_ID AND A.CUSTOMER_ID = C.CUSTOMER_ID GROUPBY C.NAME, TO_CHAR(A.ORDER_DATE, 'YYYY') ORDERBY C.NAME;
다음 부터는 CUSTOMER_SALES 로 VIEW 테이블을 조회할 수 있다.
1 2 3 4 5 6
SELECT CUSTOMER , SALES_AMOUNT FROM CUSTOMER_SALES WHEREYEAR=2017 ORDERBY SALES_AMOUNT DESC;
서브 쿼리
서브쿼리 기본
select 절에 또다른 select절이 있어서 쿼리 안에 또다른 쿼리가 있으면 서브 쿼리라고 한다.
1 2 3 4 5 6 7 8
SELECT PRODUCT_ID , PRODUCT_NAME , LIST_PRICE FROM PRODUCTS WHERE LIST_PRICE = ( SELECT MAX(LIST_PRICE) FROM PRODUCTS );
스칼라 서브 쿼리
select 중간에 쿼리가 있으면 스칼라 서브 쿼리라고 한다.
1 2 3 4 5 6 7 8 9 10
SELECT A.PRODUCT_NAME , A.LIST_PRICE , ROUND( (SELECTAVG(K.LIST_PRICE) FROM PRODUCTS K WHERE K.CATEGORY_ID = A.CATEGORY_ID ), 2 ) AVG_LIST_PRICE FROM PRODUCTS A ORDERBY A.PRODUCT_NAME;
인라인 뷰 서브 쿼리
앞서서 뷰를 보았는데 인라인 뷰도 일종의 서브 쿼리이다. 그래서 이를 인라인 뷰 서브쿼리라고 한다.
1 2 3 4 5 6 7 8 9 10 11
SELECT ORDER_ID , ORDER_VALUE FROM ( SELECT ORDER_ID , SUM( QUANTITY * UNIT_PRICE ) ORDER_VALUE FROM ORDER_ITEMS GROUPBY ORDER_ID ORDERBY ORDER_VALUE DESC ) WHERE ROWNUM <=10;
트랜잭션은 데이터베이스 시스템에서 상호작용 단위로서 어떤 기능에 한 단위라고 생가하면 된다. 예를 들어서 송금 서비스의 입근 요청부터 확인까지의 단위이나, 예매 시스템에서 좌석을 확인하고 예매까지 하는 한 뒨위라고 할 수 있다.
트랜잭션의 4대 특징(ACID)
원자성(Atomicty) : 데이터 조작이 전부 성공 혹은 전부 실패할지 보증하는 구조
일관성(Consistency) : 데이터 조작 전후에 일관성 유지, 기존의 데이터베이스가 Correct State 라면 트렌잭션을 수행하고 난 후에도 Correct State 여야 한다. -> 도메인 유효봄위, 무결성 제약조건 등의 제약조건을 위배하지 않는 정상적인 상태, 예를들어 시스템에 사용자 등록 시 등록본호에 유일성 제약을 설정하는것과, 잔액이 있어야 송금 할 수 잇다는 일관성을 지키는 것등이 있다.
고립성(Isolation) : 복수 사용자가 동시에 데이터 조작을 실행한 경우 각각의 처리가 모순 없이 실행되는 것을 보증, 트랜잭션 격리 수준
지속성(Durability) : 데이터 조작 완료 후 완료 통지 받는 시점에서 결과를 잃지 않는것, 즉 트랜잭션이 Commit 되고 나면 데이터 변경 사항이 영구적으로 확장되도록 보장하는 것
트랜잭션 처리의 필요성
원자성의 중요성
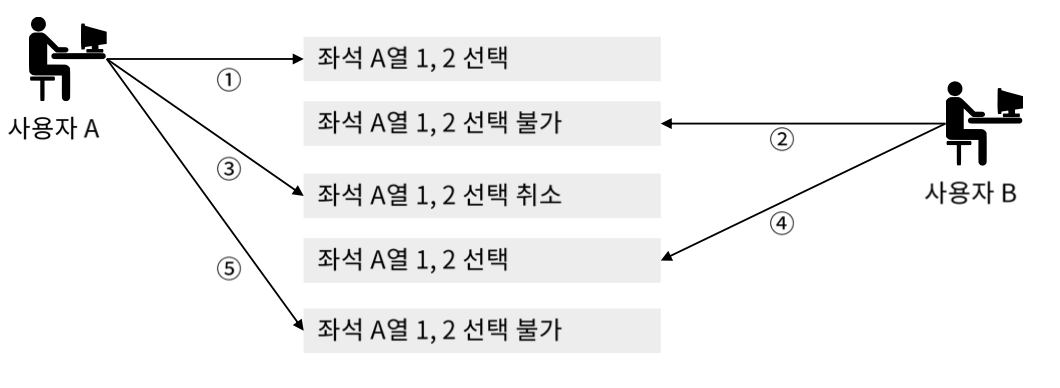
트랜잭션은 전부 성공하거나 혹은 전부 실패 해야 한다. 부분 성공이 있으면 안된다. 예를 들어서 어떤 얘매 시스템에서 좌석을 선택하고 결제단계에서 취소했다면 부분적 성공인 좌석 선택까지를 그대로 성공으로 두는 것이 아니라 모두 실패로 좌석 선택까지 실패시키는 것이다. 이렇게 해야 다른 사람이 좌석을 선택할 수 잇다.
고립성의 중요성
복수의 사용자가 트랜잭션의 모순이 없어야 한다.
격리 수준
Read Uncommitted : Commit 되지 않아도 읽기 기능, 동시성은 좋지만, 일관성은 매우 떨어짐.
Read Committed : Commit 된 내용만 읽기, 오라클 기본
Repeatable Read : 반복 읽기 중에, 내용이 업데이트 되는 것을 방지
Serializable : 직렬화 기능으로서 트랜 잭션 처리 중에 insert 도 금지
밑으로 갈수록 격리 수준은 높아지지만 Serializable 수준까지 가면 DBMS 운영 시 동시성이 크게 덜어지면서 성능 이슈가 발생한다.
격리 수준이에 따른 발생 현상
Dirty Read : 커밋되지 않은 결과도 읽어서 좋지 않은 상태
Non-Repeatable Read: 트랜잭션 중간에 어데이트를 허용해서 애매하게 읽은 상태