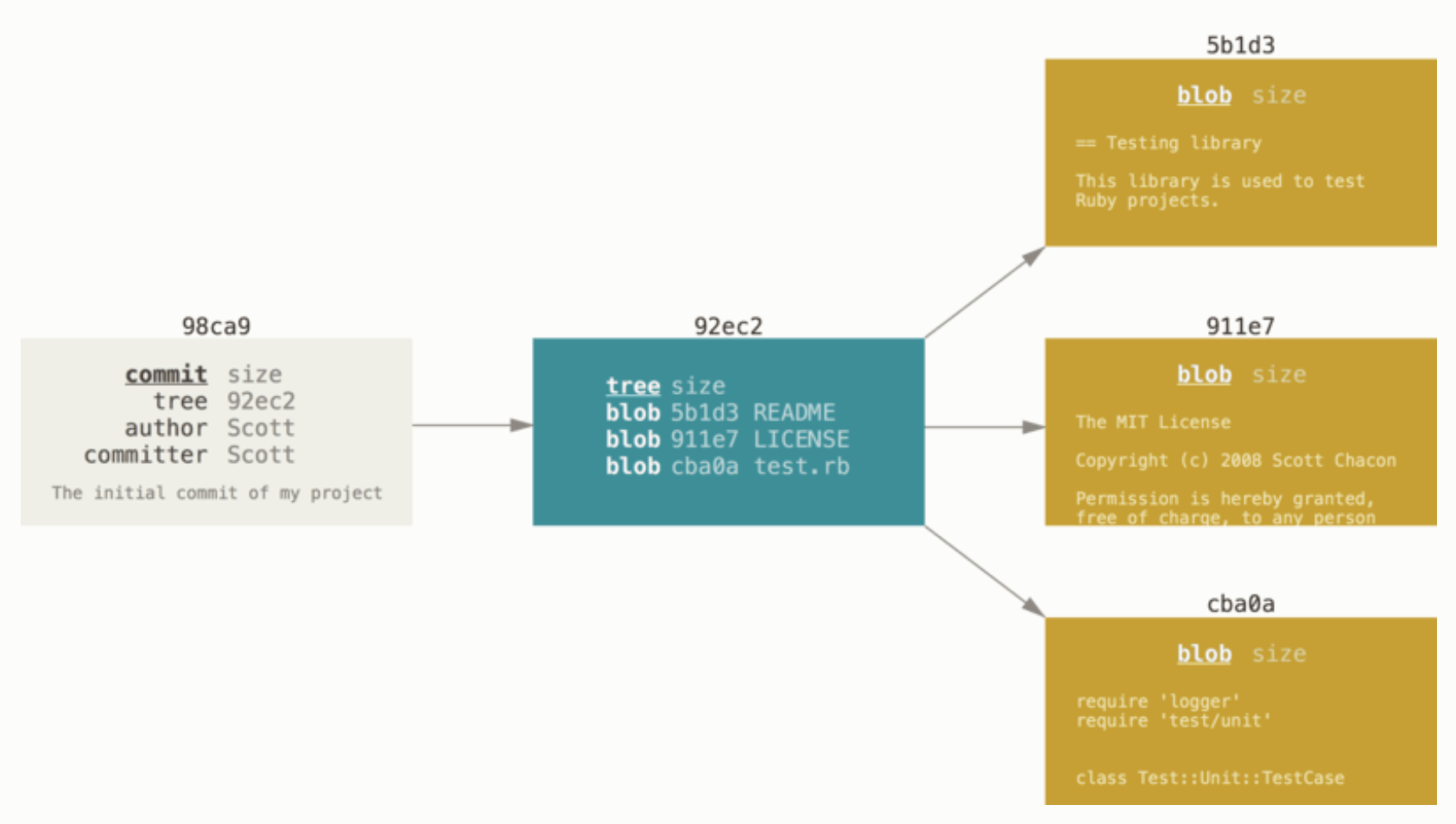
깃은 데이터를 변경 사항에 세트나 다른점으로 저장하지 않고 snapshot으로 저장한다. 커밋을 수행하게 되면 깃은 commit object를 생성한다. 각 파일에 대한 blobs를 생성하고, 파일과 디렉터리 구조를 나타내는 tree 객체를 생성한다. 커밋 객체는 루트 트리와 각 메타 데이터에 대한 포인터를 포함한다.
다른 변경사항을 커밋하면 커밋 객체는 그 바로 전에 커밋 객체를 가르키는 포인터를 갖는다.
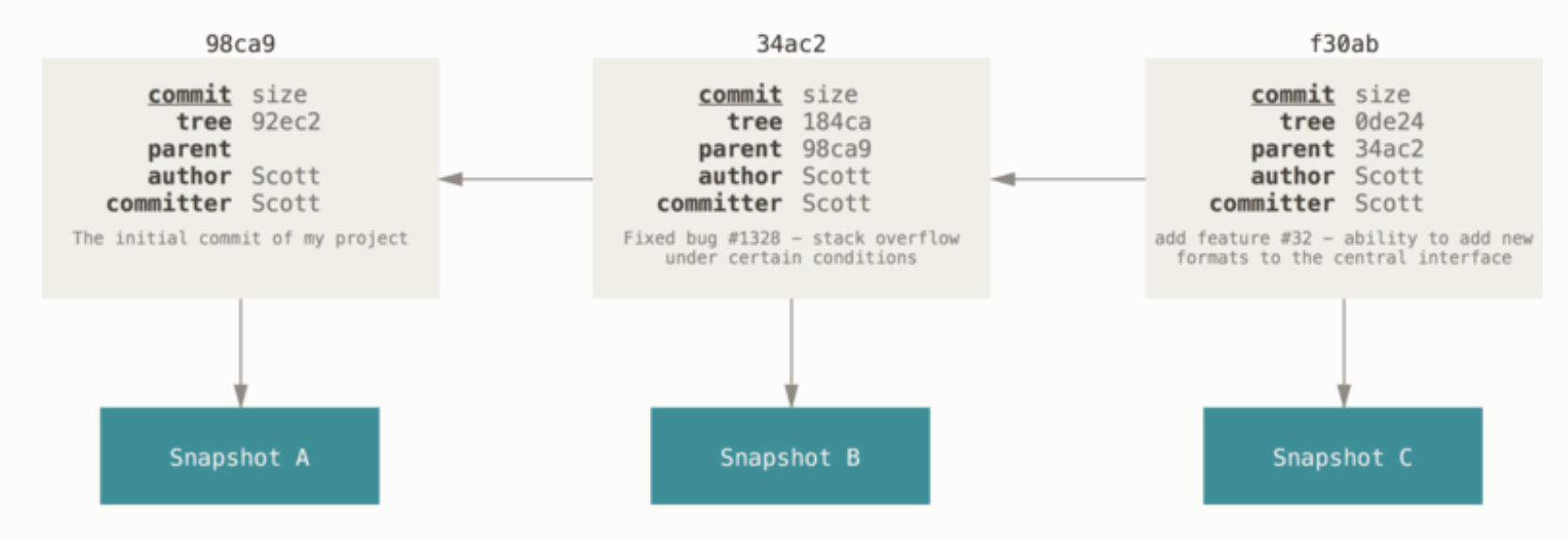
깃의 디폴드 브랜치 이름은 main이다. 처음 커밋을 하면 main 브랜치는 너가 만든 커밋을 가르킨다. 매번 커밋할때마다 main 브랜치는 자동으로 마지막으로 변경한 커밋을 가르키게 된다.
새 브랜치 생성
새로운 브랜치를 생성하면 작업한 마지막 커밋을 가르키는 브랜치가 생성된다.
1
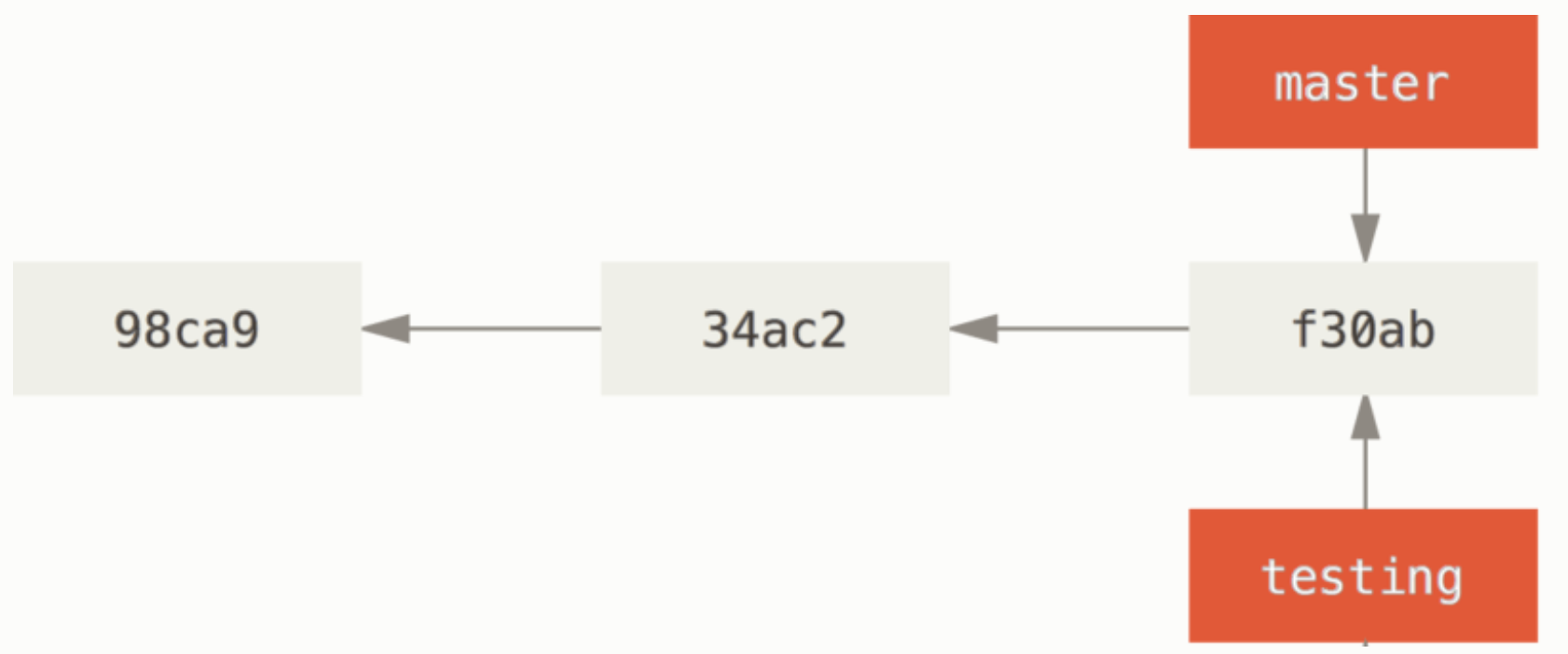
git branch testing
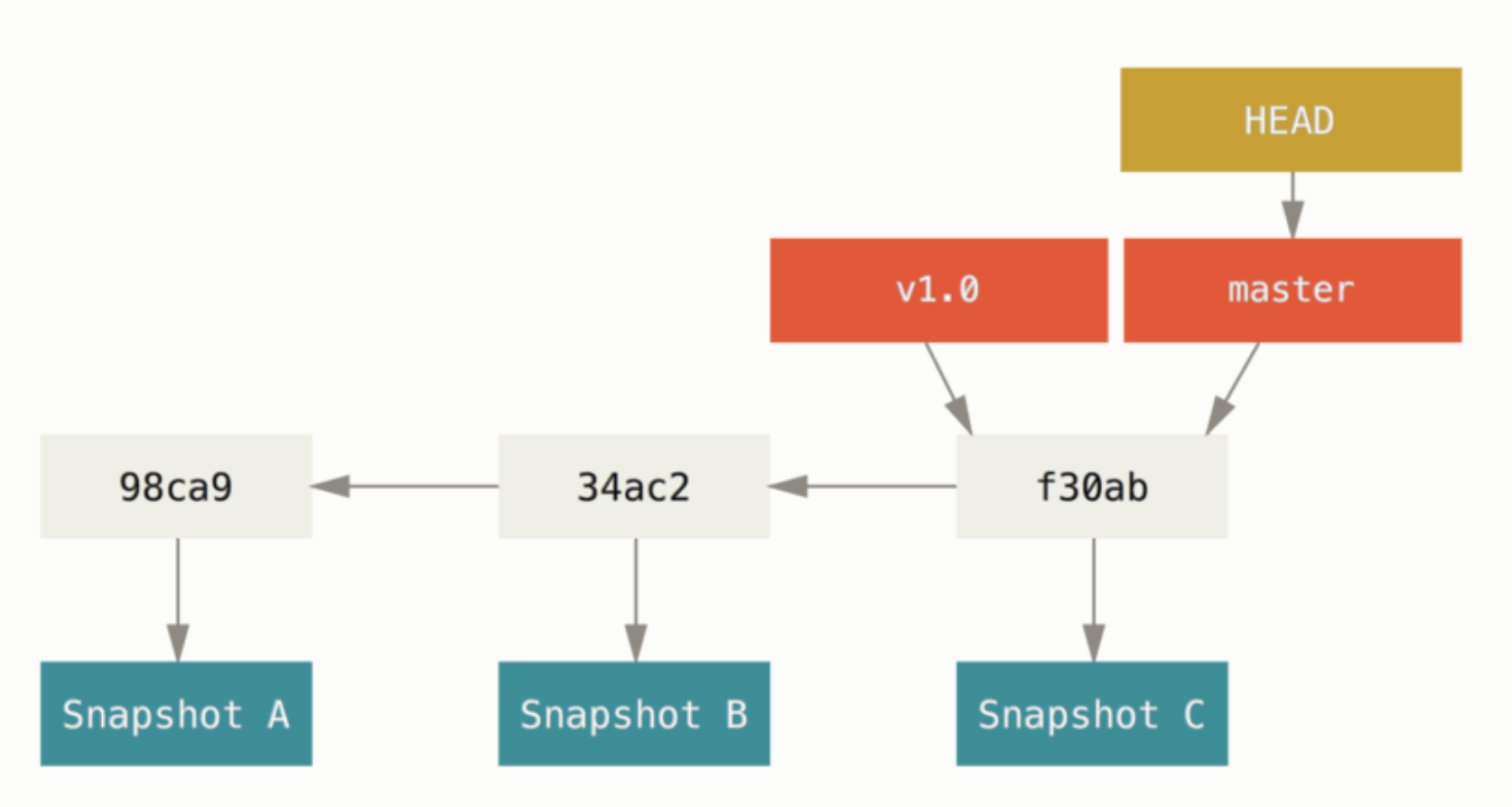
깃은 HEAD라는 포인터를 사용해서 현제 어떤 브랜치에 있는지 가르킨다. 이는 다른 버전관리 시스템과 다른 특징이다. 이것은 로컬 브랜치에서 현제 작업하고 있는 포인터이다. 브랜치를 생성해도 다른 브랜치로 스위칭 되는 것은 아니다.
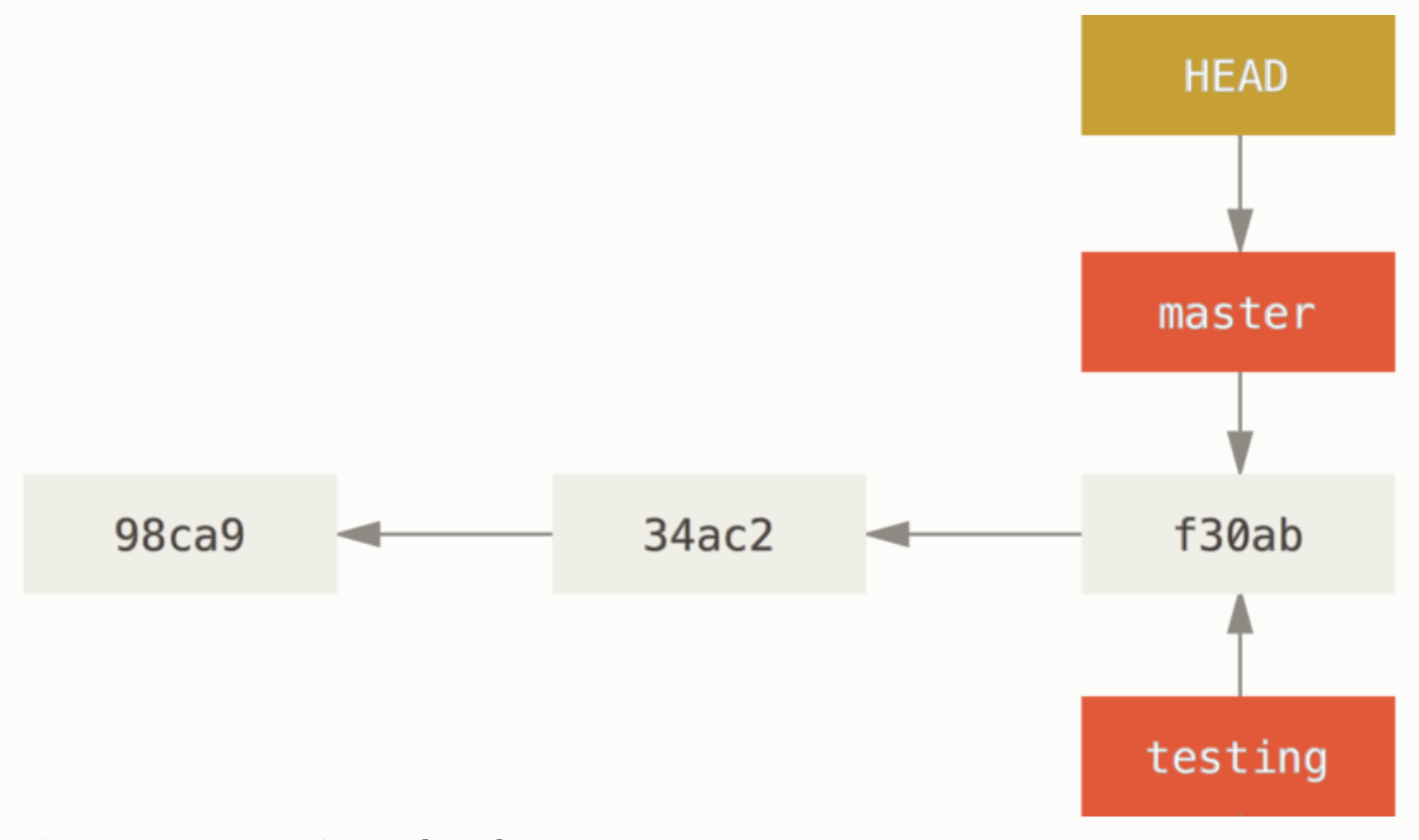
git log에 --decorate 옵션을 붙혀서 브랜치가 어떤 커밋을 가르키는지 확인할 수 있다.
git log 는 항상 모든 분기를 표시하지 않는다. 깃은 우리가 관심 있을만한 커밋에 대한 log만 보여주기 때문에 현제 작업하고 있는 브랜치에 대한 log 를 보여준다. 따라서 명시적으로 다른 브랜치에 대한 로그를 보려면 git log testing 같이 입력해야 한다. 또는, git log --all 옵션을 사용한다.
1 2 3 4
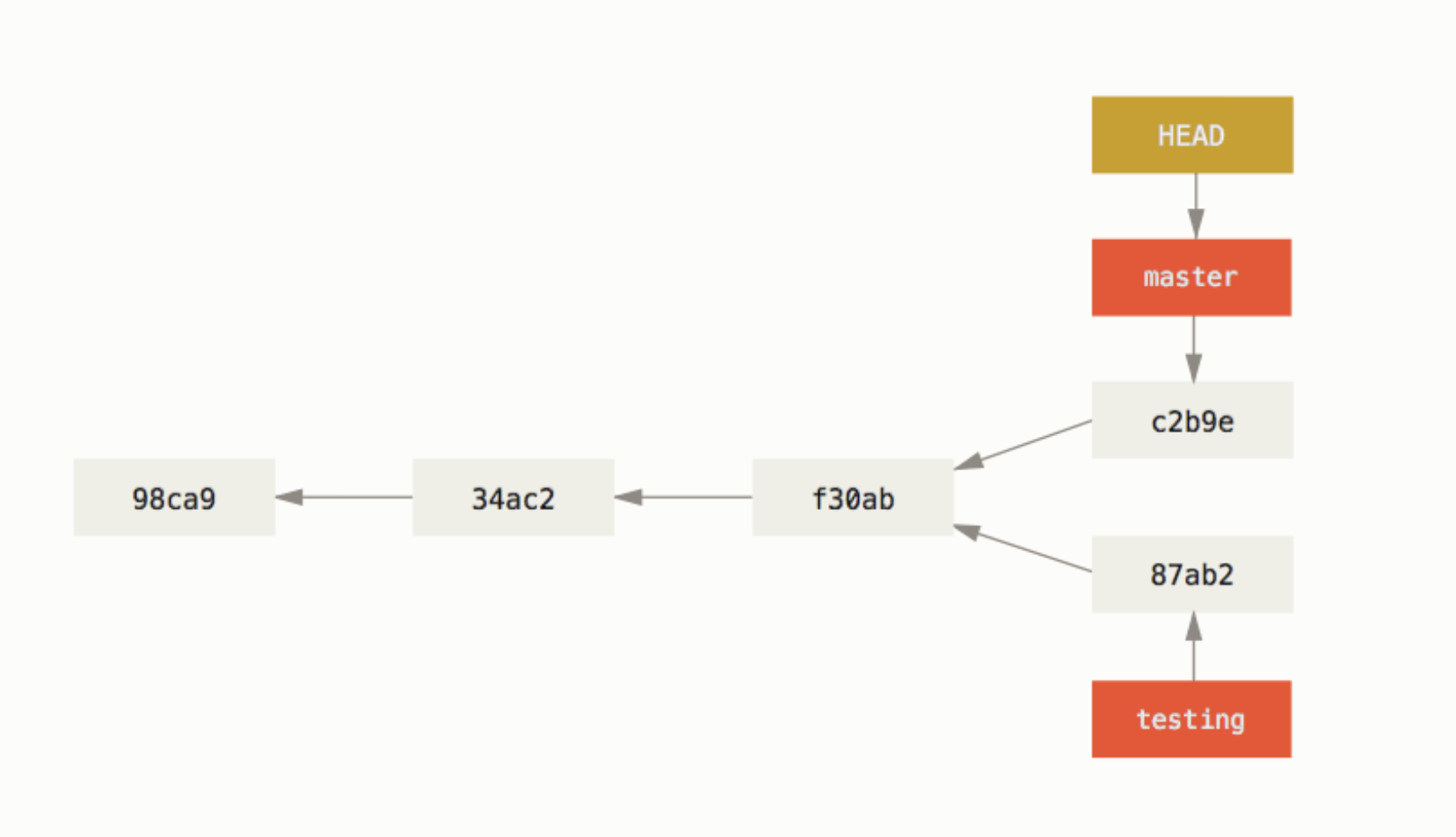
$ git log --oneline --decorate f30ab (HEAD -> master, testing) Add feature #32 - ability to add new formats to the central interface 34ac2 Fix bug #1328 - stack overflow under certain conditions 98ca9 Initial commit
Switching Branches
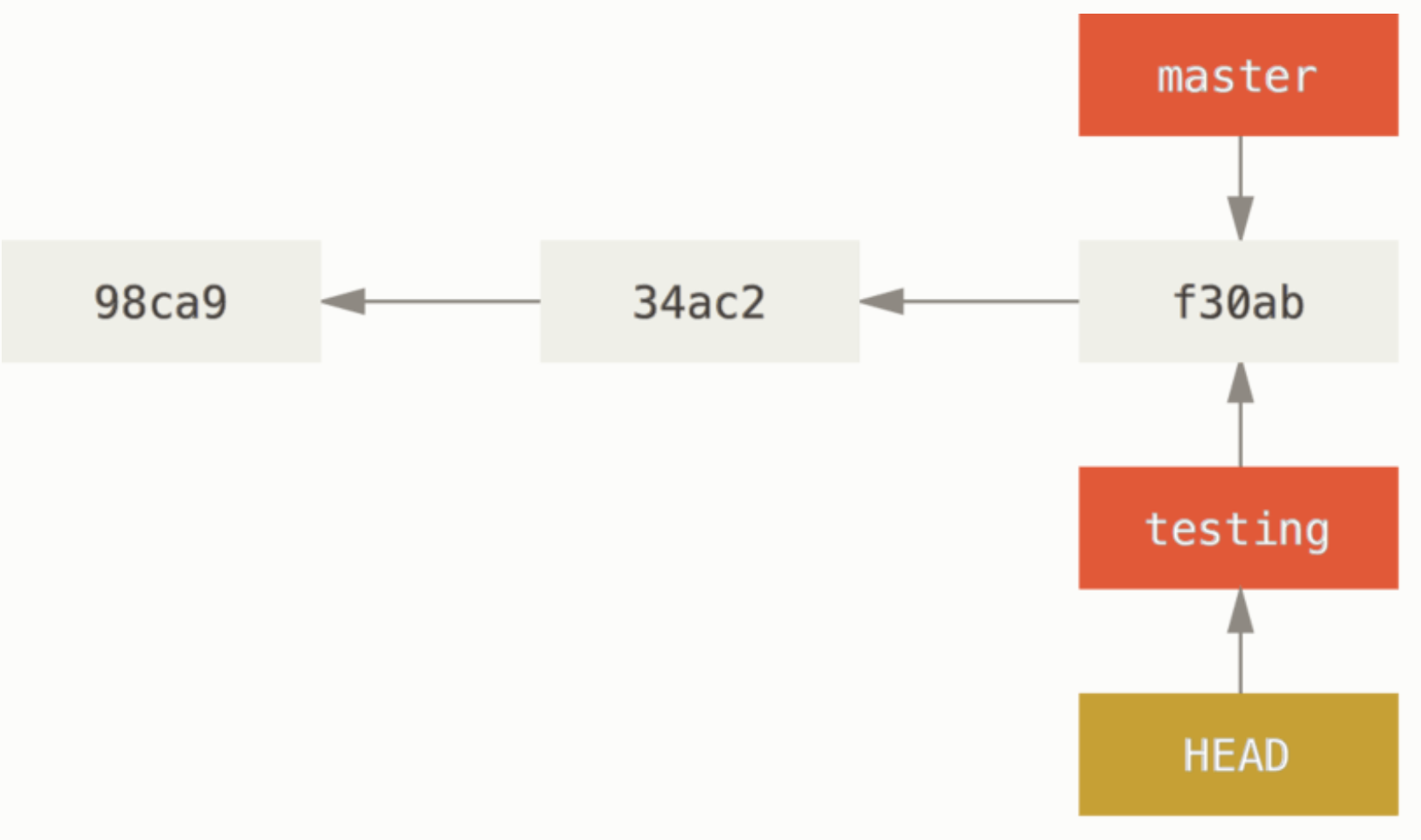
git checkout 명령어로 존재하는 브랜치로 바꿀 수 있다. 최신 버전에 깃에 경우 git switch를 통해서 바꾼다.
1
git switch testing
이 명령어는 HEAD를 master 브랜치에서 testing 브랜치로 옮긴다.
이제 다른 커밋을 하면
1 2
$ vim test.rb $ git commit -a -m 'made a change'
master 브랜치와 testing 브랜치가 가르키는 곳이 다르고 현제 작업하고 있는 포인터인 HEAD에 위치도 testing 브랜치에서 변경한 마지막 커밋으로 바뀐다.
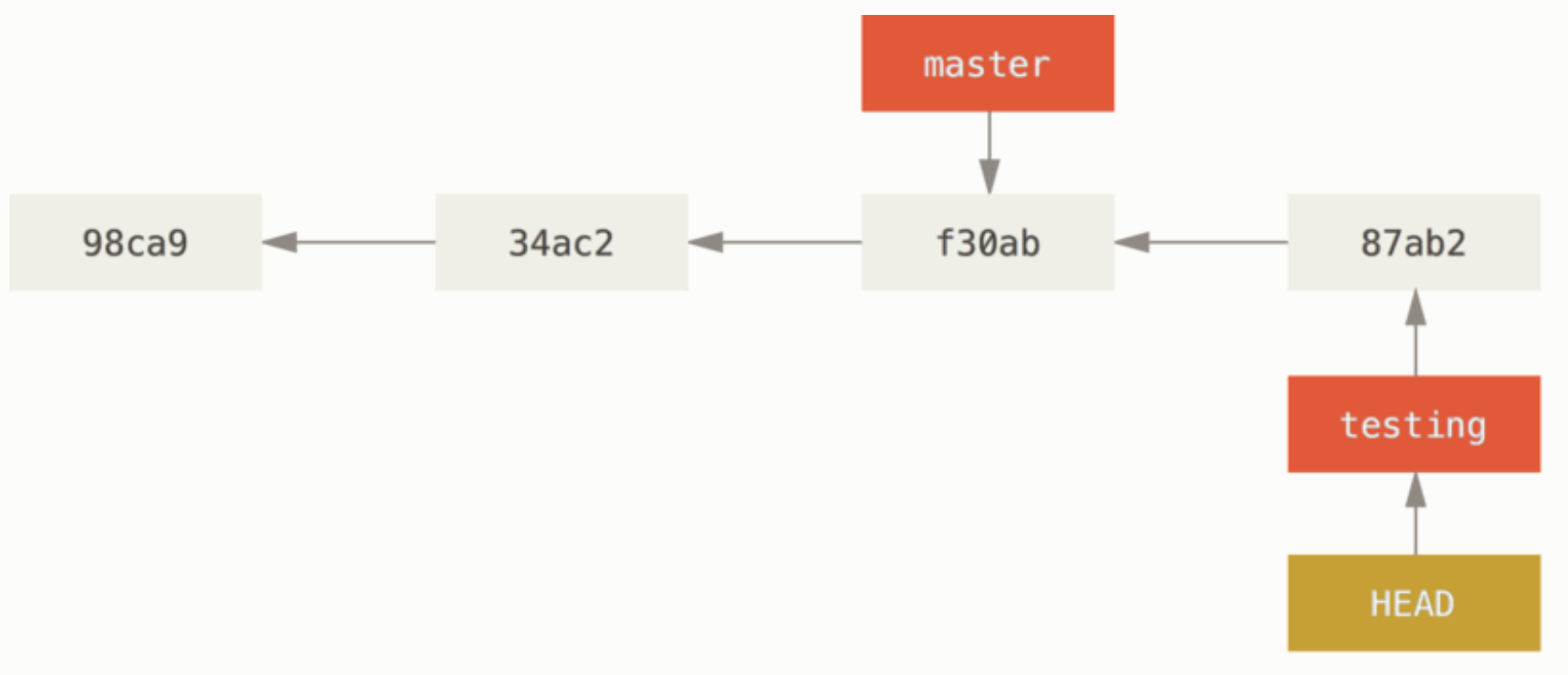
이제 다시 switch 명령을 통해 브랜치를 master로 바꿔 보자.
1
git switch master
이 명령을 입력하면 HEAD를 master 브랜치로 옮기고 파일을 마스터 브랜치가 있는 시점으로 복구한다. 이것은 예전 버전으로 복구 하는 것의 분기를 나눈 것과 같다. 또한 testing 브랜치에서 작업한 내용을 저장하고 있기 때문에 언제든지 작업한 내용으로 이동할 수 있다.
브랜치를 이동하면 워킹 디렉토리에 파일이 변경된다.
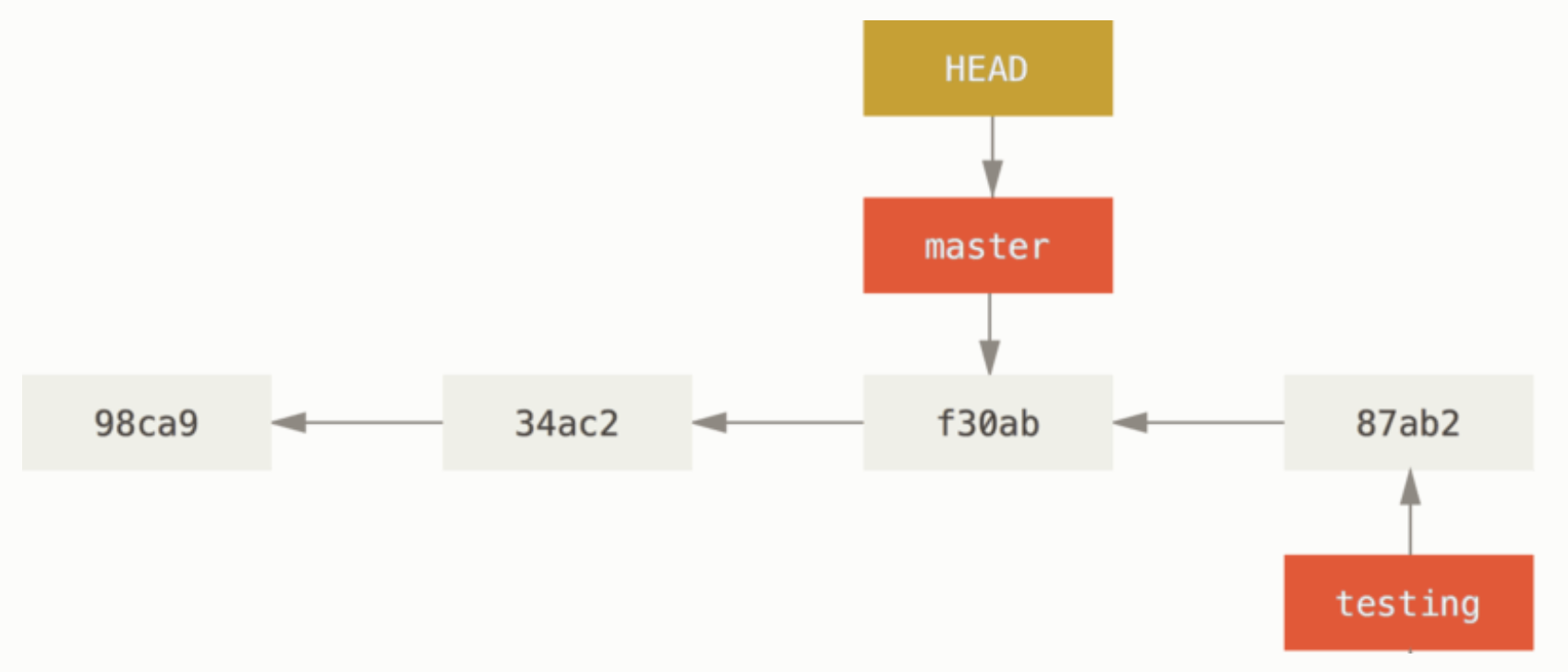
커밋을 한번 더 해보자.
1 2
$ vim test.rb $ git commit -a -m 'made other changes'
그러면 다른 작업으로 독립되어 분리된다. 이것은 testing 에서 작업하던것을 임시로 미루고 main에서 작업한 다음 다시 testing 브랜치로 돌아와 작업할 수 있음을 의미한다. 이렇게 작업하고 필요할때 merge 하는 등에 작업을 해서 하나로 합치면 된다.
git log --oneline --decorate --graph --all를 사용하면 브랜치, 분기, 포인터 history등에 정보를 한눈에 볼 수 있다.
1 2 3 4 5 6 7
$ git log --oneline --decorate --graph --all * c2b9e (HEAD, master) Made other changes | * 87ab2 (testing) Made a change |/ * f30ab Add feature #32 - ability to add new formats to the central interface * 34ac2 Fix bug #1328 - stack overflow under certain conditions * 98ca9 initial commit of my project
실제로 Git의 브랜치는 어떤 한 커밋을 가리키는 40글자의 SHA-1 체크섬 파일에 불과하기 때문에 만들기도 쉽고 지우기도 쉽다. 새로 브랜치를 하나 만드는 것은 41바이트 크기의 파일을(40자와 줄 바꿈 문자) 하나 만드는 것에 불과하다.
부모 정보도 알고 있어서 merge base를 어떤걸로 해서 merge 할지 자돋으로 알기 때문에 머지도 가볍게 잘 된다.많이 생성하고 많이 병합하세요.
git checkout -b <newbranchname> 명령어를 사용해서 한번에 생성과 switch 가지 할 수 있다.
if (pid == 0) printf("this is Child process. PID is %d\n", pid); elseif (pid > 0) printf("this is Parent process. PID is %d\n", pid); else printf("fork() is failed\n"); return0; }
fork()가 실행되면 부모 프로세스와 동일한 자식 프로세를 별도의 메모리 공간에 생성한다. 자식 프로세스에 pid 값은 0으로 리턴된다. 이때 동일한 pc 값을 가지기 때문에 이후에 코드가 실행되고 위에서 예시에선 pid > 0 일때 코드 가 출력되고 다음으로 pid == 0 일때 코드가 출력된다.
exec()
인자로 덮어씌워질 프로세스 정보를 넘겨준다. exec는 여러가지 함수 패밀리들이 있다. pc 다음부터는 코드가 덮어씌워지기 때문에 제대로 동작했으면 exec를 후출한 다음줄 부터는 실행이 안될 것이다.
intmain(){ int pid; int child_pid; int status; pid = fork(); switch(pid) { case-1: perror("fork is failed\n"); break; case0: execl("/bin/ls", "ls", "-la", NULL); perror("execl is failed\n"); break; default: child_pid = wait(NULL); printf("ls is complete\n"); printf("Parent PID (%d), Child PID (%d)\n", getpid(), child_pid); exit(0);
} }
execl를 호출하면 부모 프로세스가 덮어씌어 지니까 fork를 통해 자식 프로세스 생성. case 0 인 경우는 자식 프로세스 인 겨으로 여기에 ls 명령어를 덮어씌움.
ls 명령어 출력
wait()를 통해서 자식 프로세스가 끝나기를 기다렸다가 부모 프로세스를 실행 시킬 수 있음.
copy-on-write
리눅스에 프로세스 크기는 4GB에 크기를 가지는데 fork()로 복제할때마다 전체를 복사하려고 하면 오래 걸린다. 따라서 자식 프로세스를 생성했다면 우선은 부모 프로세스에 페이지를 같이 굥유하는 방법으로 생성한다. 그리고 페이지를 읽는 것이 아니라 써야 할때 페이지를 복사하고 분리하는 방법을 사용한다.
장점
프로세스 생성 시간을 줄일 수 있다.
새로 생성된 프로세스에 새롭게 할당되어야 하는 페이지 수도 최소화 된다.
프로세스 종료
exit() 세스템콜 : 프로세스 종료
c 언어에서 main 함수에서 return 을 호출하는 것과 exit()을 호출하는 것에는 어떤 차이가 있을까?
c 언어 실행 파일은 우선 _start() 함수를 호출하고 그 안에서 main() 함수를 호출함. return 하면 main 함수가 끝나고 다음 exit()함수를 호출함.
만약 main 함수에서 exit() 함수를 호출했다면 바로 프로세스를 종료시키는 것임.
exit() 시스템 콜
부모 프로세스는 status & 0377 계산 값으로 자식 프로세스 종료 상태 확인 가능
기본 사용
1 2
exit(EXIT_SUCCESS); exit(EXIT_FAILURE);
주요 동작
atexit() 에 등록된 함수 실행
열려 있는 모든 입출력 스트림 버퍼 삭제
프로세스가 오픈한 파일을 모두 닫음
tempfile() 함수를 생성한 임시 파일 삭제
atexit() 함수
프로세스 종료시 실행될 함수를 등록하기 위해 사용한다. 등록된 함수를 등록된 역순서대로 실행한다.
intmain(void){ voidexithandling(void); voidgoodbymessage(void); int ret;
ret = atexit(exithandling); if (ret != 0) perror("Error in atexit\n"); ret = atexit(goodbymessage); if (ret != 0) perror("Error in atexit\n"); exit(EXIT_SUCCESS); }
%20운영체제/1.png)





